


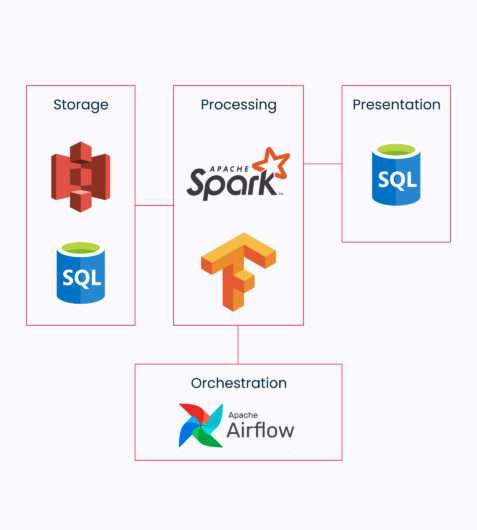

Manufacture

Education & E-Learning

Services

AWS DevOps

Power BI

Power Apps

OpenAI’s ChatGPT Optimizing Language Models for Dialogue
OpenAI’s ChatGPT Overview : Did you hear about ChatGPT while browsing and skimming your social media last week? The announcement…

Top 10 No-code App Development Services and Platforms For Your Startup
No code App Development Services What is a No-Code Platform? No code development platform is an application that provides GUI…

How to upgrade Dynamics NAV To Dynamics 365 Business Central
Microsoft upgrade Dynamics NAV has significantly conquered the market’s throne and brings in massive business opportunities. It looks like the…

Why ASO is essential for your business app to Improve Visibility in the app stores?
What is ASO? App Store Optimization (ASO) is a process to improve app visibility within app stores. It helps to…
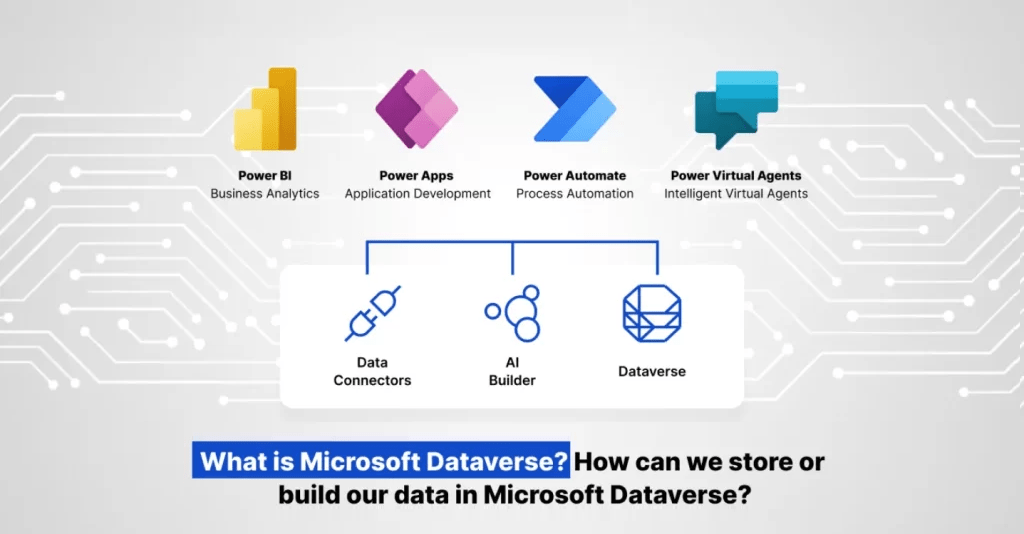
What is Microsoft Dataverse? How can we store or build our data in Microsoft Dataverse?
What’s Microsoft Dataverse for Teams? Microsoft Dataverse for Teams is a lite version of Dataverse. It designed to build a…

Why you need to use .NET Core instead of ASP.NET?
Understand the difference .Net core vs ASP.Net Framework Both .Net core development and ASP.Net framework are maintained by Microsoft and…

Why React Native Is Considered The Most Cost-Effective Platform For Mobile App Development?
What Are The Benefits Of React Native Over Android And iOS-Based Apps In this section, we will have a look…